What Happens When You Give an AI Agent Your AWS Credentials
The interface you give AI agents determines what they can break.

Teams are getting more comfortable shipping AI-generated backend code to production, but most of them still keep agents away from infrastructure entirely. A human writes the Terraform, a ticket or Slack message connects it to the agent's application code, and the infrastructure side moves at the same speed it always did. Some teams are starting to let agents write Terraform directly, which removes the coordination step but opens up the full AWS API surface to whatever the agent decides to configure.
We've been thinking about this at Encore for a while, since our framework derives infrastructure directly from application code. That architecture turns out to matter a lot when agents are the ones writing the code, for reasons that become clear once you look at what the alternatives actually involve.
Keeping agents away from infrastructure
The safest approach is to not let agents touch infrastructure at all. The agent writes application code, a human writes the matching Terraform, and a ticket or a Slack message connects the two. This is what most teams are doing today, and it works in the sense that nothing goes wrong with the infrastructure.
The cost is that it reintroduces the exact bottleneck that AI coding tools were supposed to remove. We covered this in The Last Year of Terraform: the agent generates code in minutes, but the infrastructure to run it takes the rest of the day once you factor in the second PR, the second review, the plan/apply cycle, and the staging verification. The agent is fast, but the system around it isn't, and features sit in PRs waiting for someone to provision a database.
For teams with a strong platform engineering function that can keep pace, this is a perfectly reasonable model. How long that pace holds depends on how much agent output your team is producing.
Giving agents Terraform access
Some teams are going the other direction. The agent writes a service, then writes the matching .tf files: the RDS module, the IAM policy, the security groups, the SNS+SQS configuration. HashiCorp themselves have noted that a large portion of new Terraform configurations is already being authored by AI, and they've released a Terraform MCP server to help LLMs generate more accurate HCL. A Terrateam evaluation found that AI-generated Terraform can reduce dev time by 60-70%, though it requires human review and security scanning.
The writing part gets faster, but the implications are different from letting an agent write application code, because Terraform exposes the full API surface of your cloud provider. That's the point of it, and it's what makes it useful for human operators who understand the implications of what they're configuring. An RDS module can specify a private subnet, encryption at rest, automated backups, and a security group scoped to the application's VPC. It can also specify a public endpoint with no encryption and a security group open to 0.0.0.0/0. Both are valid HCL, and the difference between them is the kind of thing a platform engineer catches in review.
When a human writes a few Terraform changes per week, that review process works. When an agent generates ten services in an afternoon, each with its own Terraform module, the reviewer is looking at hundreds of lines of HCL across multiple PRs. The surface area for a misconfiguration to slip through scales linearly with the volume of agent output.
Cloud misconfiguration is already the most common security issue in production environments. Wiz's 2025 cloud security report found that 72% of cloud environments have publicly exposed PaaS databases lacking access controls. A Qualys analysis of one automotive company's data leak traced 70+ TB of exposed data, including customer databases, fleet telemetry, and internal systems, back to hard-coded AWS keys and publicly accessible S3 buckets. Adding AI-generated Terraform to that baseline doesn't make the numbers go down.
A misconfigured IAM policy or security group can expose a database to the public internet, and unlike a broken endpoint that someone notices immediately, the feedback loop between the misconfiguration and its discovery can be weeks or months.
Teams with mature Terraform review processes, strong CI/CD guardrails, and platform engineers who understand the blast radius are making this work. The review burden does grow with every service the agent produces, and that's worth factoring in.
Policy checks as guardrails
The standard response to this is policy enforcement. Tools like Open Policy Agent, Sentinel, tfsec, and Checkov scan Terraform plans and reject configurations that violate a set of rules, like public S3 buckets, wildcard IAM policies, or unencrypted databases.
These tools are useful and most teams should be running them regardless of whether AI agents are involved. The issue is that they're a blocklist approach applied to an unconstrained space. You define everything the agent shouldn't do, and everything else is implicitly allowed. Every new AWS resource type, every new configuration parameter, every new service is allowed by default until someone writes a rule to block the dangerous configurations.
AWS has over 1,500 resource types with thousands of configuration parameters across them. Writing OPA policies that cover the combinations that matter is substantial ongoing work, and you're always responding to what the agent already tried rather than preventing it structurally. The security team writes a policy blocking public RDS instances. A month later the agent starts using Aurora Serverless, which has a different configuration surface. The existing policy doesn't cover it, and nobody catches it until the next security audit.
OPA and similar policy tools are valuable regardless of whether agents are involved, and running them is good practice for any team. Where it gets harder is when the volume of configurations to check grows faster than the policies to check them against.
Bounding the interface instead of policing the output
Instead of giving agents access to the cloud API surface and adding checks on top, you can give them an interface where the dangerous configurations aren't expressible in the first place. Infrastructure from code takes this approach: the agent writes application code that declares what the service needs using typed primitives, and the platform handles the actual cloud provisioning:
import { SQLDatabase } from "encore.dev/storage/sqldb";
import { Topic } from "encore.dev/pubsub";
import { api } from "encore.dev/api";
// Declares a PostgreSQL database. Encore provisions it automatically
// (Docker locally, RDS or Cloud SQL in production).
const db = new SQLDatabase("orders", { migrations: "./migrations" });
// Declares a Pub/Sub topic. Becomes SQS on AWS, Pub/Sub on GCP.
const events = new Topic<OrderEvent>("order-events", {
deliveryGuarantee: "at-least-once",
});
// A type-safe API endpoint. Encore handles routing, validation,
// and generates API docs automatically.
export const create = api(
{ expose: true, method: "POST", path: "/orders" },
async (req: CreateOrderRequest): Promise<Order> => {
const order = await db.exec`
INSERT INTO orders (customer_id, total)
VALUES (${req.customerId}, ${req.total})
RETURNING *`;
await events.publish({ orderId: order.id, type: "created" });
return order;
}
);
The agent declared a database and a pub/sub topic. The interface has no parameters for subnets, instance types, IAM policies, or security groups, so there's nothing to misconfigure at that level. The platform provisions the actual cloud resources based on environment-level configuration that the infrastructure team sets once: private subnets, encryption at rest, least-privilege IAM, whatever the organization's policies require. Every service inherits the same configuration regardless of whether a human or an agent wrote it.
With Terraform, the agent can touch any of the 1,500+ AWS resource types and thousands of configuration parameters. With infrastructure from code, the agent works with a bounded set of typed primitives:
| Terraform | Infrastructure from Code | |
|---|---|---|
| Database | aws_db_instance + subnet group + security group + parameter group + IAM | new SQLDatabase("orders") |
| Pub/Sub | aws_sns_topic + aws_sqs_queue + DLQ + IAM policy + subscription | new Topic<OrderEvent>("events") |
| Cron | aws_cloudwatch_event_rule + Lambda + IAM role + log group | new CronJob("cleanup", { every: "1h" }) |
| Storage | aws_s3_bucket + policy + encryption + lifecycle + CORS | new Bucket("uploads") |
| Networking | VPC + subnets + NAT + route tables + security groups | Configured in your cloud account based on your application's service graph |
| IAM | Roles + policies + trust relationships per resource | Auto-generated per service with least-privilege scoping |
The agent can't misconfigure networking or IAM because those aren't part of the interface. The platform derives them from your application's metadata and provisions them in your own AWS/GCP account following security best practices. The infrastructure team configures the baseline once per environment, and every service inherits it.
Encore works this way. The infrastructure primitives (databases, Pub/Sub, cron jobs, object storage, caching) are typed constructors in TypeScript or Go. The Rust-based compiler validates them at build time: wrong pub/sub payload type, missing migration directory, invalid API contract are all compile errors that surface before anything deploys. The agent gets feedback in the same loop where it writes the code, not days later in staging. The blast radius of what the agent can do is bounded by the type system of the framework rather than the API surface of AWS.
Because the compiler builds a complete graph of services, APIs, and infrastructure dependencies, the platform can surface that as a visual architecture map that updates automatically as the code changes:
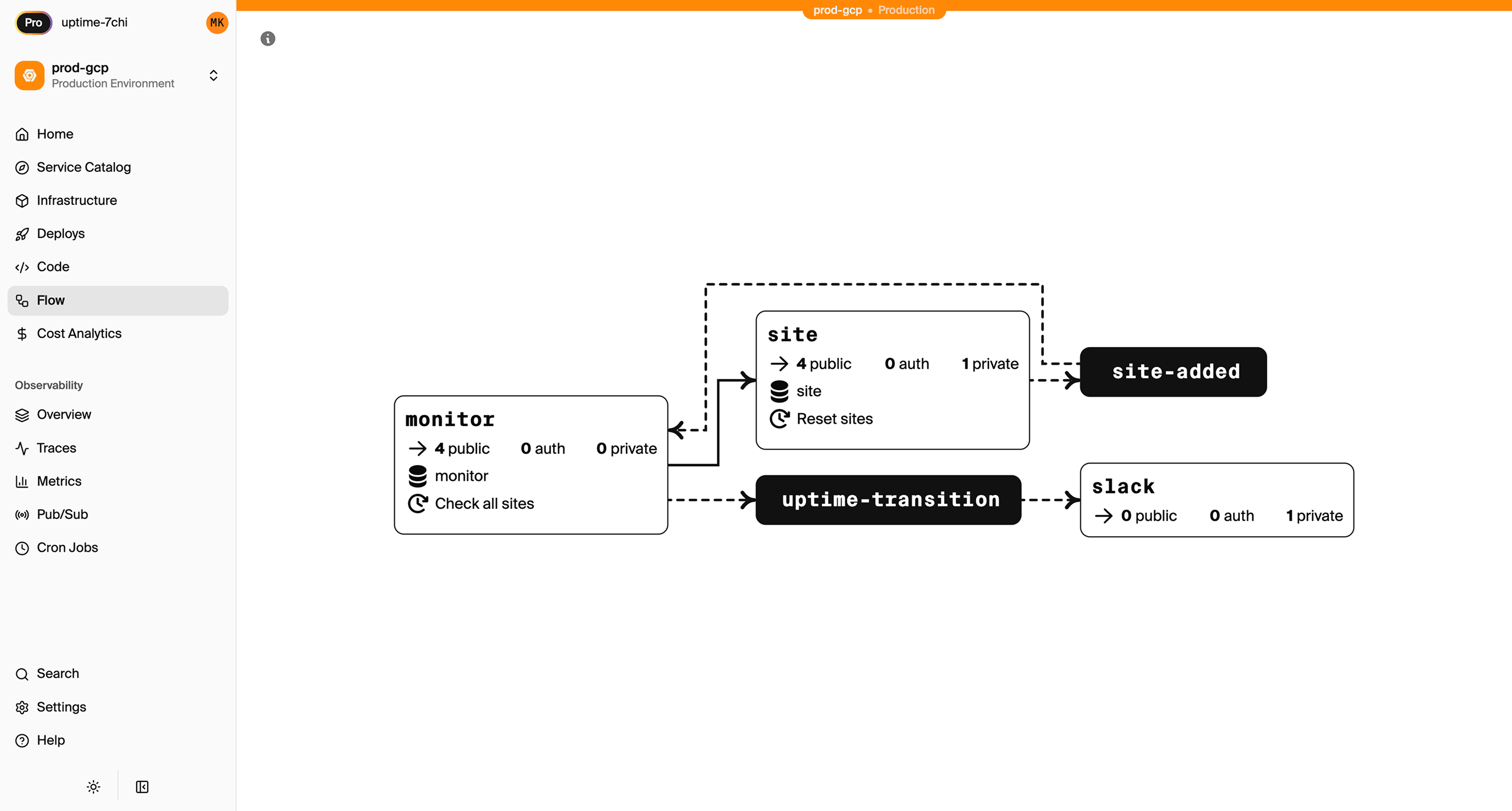
What reviewing agent-generated infrastructure looks like
Reviewing agent-generated Terraform means reading HCL and mentally simulating what terraform plan will produce. You're looking at resource blocks, data sources, variable interpolation, IAM policy documents, and trying to verify that the resulting infrastructure is both correct and secure. That takes domain expertise in both the application and the cloud provider, and it takes time that scales with the volume of changes.
When infrastructure is declared in application code instead, the PR contains TypeScript with typed infrastructure declarations. A new SQLDatabase is three lines, a new Topic is two, and the reviewer reads the same language the application is written in. The infrastructure implications are visible in the type signatures rather than in a separate set of files written in a different language.
When agent-generated code is pushed, the platform shows what infrastructure will be created or modified and the infrastructure team can approve or reject changes before anything is provisioned. The approval is on the deploy, not on the code, which means you get a complete picture of what's about to change rather than reviewing infrastructure code in isolation from the application it supports.
The access question reframed
The instinct when thinking about AI agents and cloud infrastructure is to focus on access control: tighter IAM roles, shorter-lived credentials, more granular permissions. Obsidian Security's research on the AI agent security landscape highlights token compromise as the top threat, since agents typically use long-lived API tokens and credential sprawl compounds the risk as organizations deploy more of them. Tightening credentials is good practice regardless.
But giving an agent narrow IAM permissions in AWS is still giving it access to the AWS API. You're constraining what it can do within an unconstrained system, which is the same architecture as policy checks: a set of constraints carved out of a space that's open by default. The maintenance burden follows the same pattern, where every new capability the agent needs requires updating the permissions, and every permission you grant is a surface area you're responsible for.
With infrastructure from code, the agent writes application code with typed infrastructure declarations and the platform handles the cloud API calls within constraints the infrastructure team configured. The agent describes what the application needs, and a separate system with its own controls decides how to provision it. AWS credentials never enter the picture.
Where this is heading
The tools are ahead of the workflows right now. Agents can write production-quality application code, but most teams don't have infrastructure workflows designed for agent-generated output at the volume agents produce it. Terraform was built for human operators making deliberate, carefully reviewed changes. That model worked for a decade, and the investment teams have made in it is real.
But the volume of code changes is increasing, and every change that touches infrastructure creates a coordination problem. Teams that have collapsed the boundary between application code and infrastructure, where the agent writes typed code and the platform provisions within guardrails, are deploying agent-generated services without a separate infrastructure step and without giving agents access to their cloud accounts.
AI agents are already provisioning infrastructure through Terraform modules, CDK constructs, and Pulumi programs that teams review with varying degrees of thoroughness. Each approach to handling that makes a different set of tradeoffs:
| Approach | Agent writes infra? | Blast radius | Review burden | Deployment speed | Best for |
|---|---|---|---|---|---|
| Agent writes code, human writes Terraform | No | Contained | Moderate (app code + human-written HCL) | Slow (two PRs, two reviews) | Teams with dedicated platform engineers |
| Agent writes Terraform + policy checks | Yes | Full cloud API, constrained by policies | High (HCL + policies) | Fast (one PR) | Teams with mature IaC review processes |
| Infrastructure from code | Indirectly (typed primitives) | Bounded by type system | Low (same language as app) | Fast (one PR) | Teams without dedicated platform engineers |
Every team is somewhere on this spectrum. Some have platform engineers who can review Terraform at the pace agents produce it, and policy tooling that covers their cloud surface. That works today and will keep working as long as the review capacity scales with the output. Other teams are smaller, moving faster, and don't have the infrastructure expertise to maintain that process. For them, constraining what the agent can express in the first place removes a category of problems they'd otherwise need to staff for. The interesting thing happening right now is that the volume of agent-generated code is pushing teams to make this decision explicitly, where before it was something they could defer. However your team handles it, the infrastructure workflow you have today is going to see a lot more code flowing through it than it was designed for.
Encore is an open-source backend framework where infrastructure is declared in TypeScript or Go and provisioned from the code. GitHub.
Related Articles

 Ivan Cernja
Ivan Cernja Ivan Cernja
Ivan Cernja Ivan Cernja
Ivan Cernja