The Last Year of Terraform
Terraform solved the right problem. AI just made it the wrong answer.

AI agents are writing production backend code now, from database queries to pub/sub handlers to API endpoints. GitHub's 2025 Octoverse found that 30 to 50 percent of enterprise code is AI-generated. Google reported over 30%. The rate keeps climbing, and every team building with these tools is hitting the same wall: the code arrives in minutes, but the infrastructure to run it takes the rest of the day.
Terraform was designed for a world where infrastructure changed a few times a week and each change was reviewed carefully before being applied. That cadence no longer exists. DORA's research on AI-assisted development found that writing code faster with AI doesn't speed up delivery unless the workflows around the code change too, and nearly half of organizations cite "too many repetitive tasks" as a key infrastructure pain point. Infrastructure provisioning is the workflow that hasn't changed.
Ask an AI agent to add an order service with a database, an event topic, and an API endpoint. The application code comes back in a few minutes: a few files, a few hundred lines of TypeScript or Go, standard patterns.
But in a project that manages infrastructure through Terraform, that application code is maybe a third of what needs to happen. The agent also needs to produce, or someone needs to write:
- A Terraform module for the RDS instance with connection pooling, backup configuration, and security groups
- A Terraform module for SNS + SQS with dead letter queues and retry policies
- IAM policy documents scoping access to the new resources
- An update to the CI/CD pipeline to include the new service
- A Docker Compose change so the service runs locally with the right database and queue bindings
- Environment variable configuration for each deployment target
The agent writes code in about two minutes. With Terraform, getting that code to production takes the better part of a day once you add the reviews, plan/apply cycles, and staging verification. With infrastructure from code, one review and a git push.
An agent can write the Terraform too, of course. But the bottleneck was never typing the .tf files. It's the two separate PRs, the two review cycles, the plan and apply in staging and production, and keeping two codebases in sync. Automating the writing doesn't touch any of that.
Why Terraform made sense
Before Terraform, infrastructure was provisioned through cloud consoles and bash scripts. Someone SSH'd into a box and ran commands. When they left, nobody knew what was running or why. Terraform changed that: infrastructure became version-controlled, reviewable, reproducible. Teams could collaborate on infrastructure the same way they collaborated on application code.
That was a real improvement. But it created a separation between application code and infrastructure code that nobody questioned for a decade. The application developer writes business logic. The platform engineer writes Terraform. A ticket connects the two. Two repositories, two review processes, two deployment pipelines, two sets of expertise.
When both sides moved at a similar pace, the separation was fine. A developer shipped a few features per sprint, and a platform engineer kept up. The ceremony around terraform plan and terraform apply was proportional to the volume of changes.
What happens at AI pace
When an agent generates ten new endpoints in an afternoon, nobody writes the ten Terraform modules to match. The infrastructure is a separate system maintained by a separate team with a separate deployment pipeline, and it moves at its own speed regardless of how fast the application code arrives.
Agent opens a PR with application code. A human reviews it. A platform engineer opens a second PR with the Terraform changes. Another review. A terraform plan. A terraform apply in staging. Manual verification. Then production, with its own plan and apply cycle. If anything drifts between the two PRs, debugging starts.
Most teams can absorb a few infrastructure changes per week. Agents produce code continuously, and every change needs its infrastructure counterpart. Features sit in PRs waiting for Terraform.
Just have the agent write the Terraform
Some teams are trying this. The agent writes a service, then writes the matching .tf files. The writing gets faster, but the architecture stays the same: three interdependent layers that must stay in sync.
The application code references a database. The Terraform defines how that database is provisioned. The CI/CD pipeline and Docker Compose define how it's deployed and run locally. Change any one layer and the other two need updating. Add a pub/sub topic in the application code and you need a matching SNS+SQS module in Terraform and a new container in Docker Compose. Rename a database and the migration, the Terraform resource, and the environment variables all need to agree.
An agent can generate all three layers, but it can't eliminate the coupling between them. Every change is a coordination problem across languages, tools, and deployment processes. The more code the agent produces, the more coordination surfaces it creates.
What infrastructure from code looks like
Infrastructure from code isn't new. Encore has been shipping this since before the current wave of AI tools, and the core idea of deriving infrastructure from application code has been around even longer. Terraform worked, teams had invested in it, and the case was never urgent enough to force a move. AI agents changed the math. When the volume of code changes outpaces what a separate infrastructure process can absorb, collapsing the two into one system stops being a nice-to-have and becomes the bottleneck you either fix or build around forever.
The approach is straightforward. Instead of writing Terraform separately, you declare what your service needs in the application code:
import { SQLDatabase } from "encore.dev/storage/sqldb";
import { Topic } from "encore.dev/pubsub";
import { api } from "encore.dev/api";
const db = new SQLDatabase("orders", { migrations: "./migrations" });
const orderTopic = new Topic<OrderEvent>("order-created", {
deliveryGuarantee: "at-least-once",
});
export const createOrder = api(
{ expose: true, auth: true, method: "POST", path: "/orders" },
async (req: CreateOrderRequest): Promise<Order> => {
const order = await db.exec`
INSERT INTO orders (customer_id, total)
VALUES (${req.customerId}, ${req.total})
RETURNING *`;
await orderTopic.publish({ orderId: order.id, total: order.total });
return order;
}
);
The database, the pub/sub topic, the API routing, request validation, IAM roles, and tracing are all derived from this code. No Terraform module. No Docker Compose file. No CI/CD pipeline update. The same code runs locally with real infrastructure, in preview environments per PR, and in production on AWS or GCP. In Encore's case, the provisioned infrastructure is visible in a dashboard where infrastructure teams can inspect resources, configuration, and status across environments:
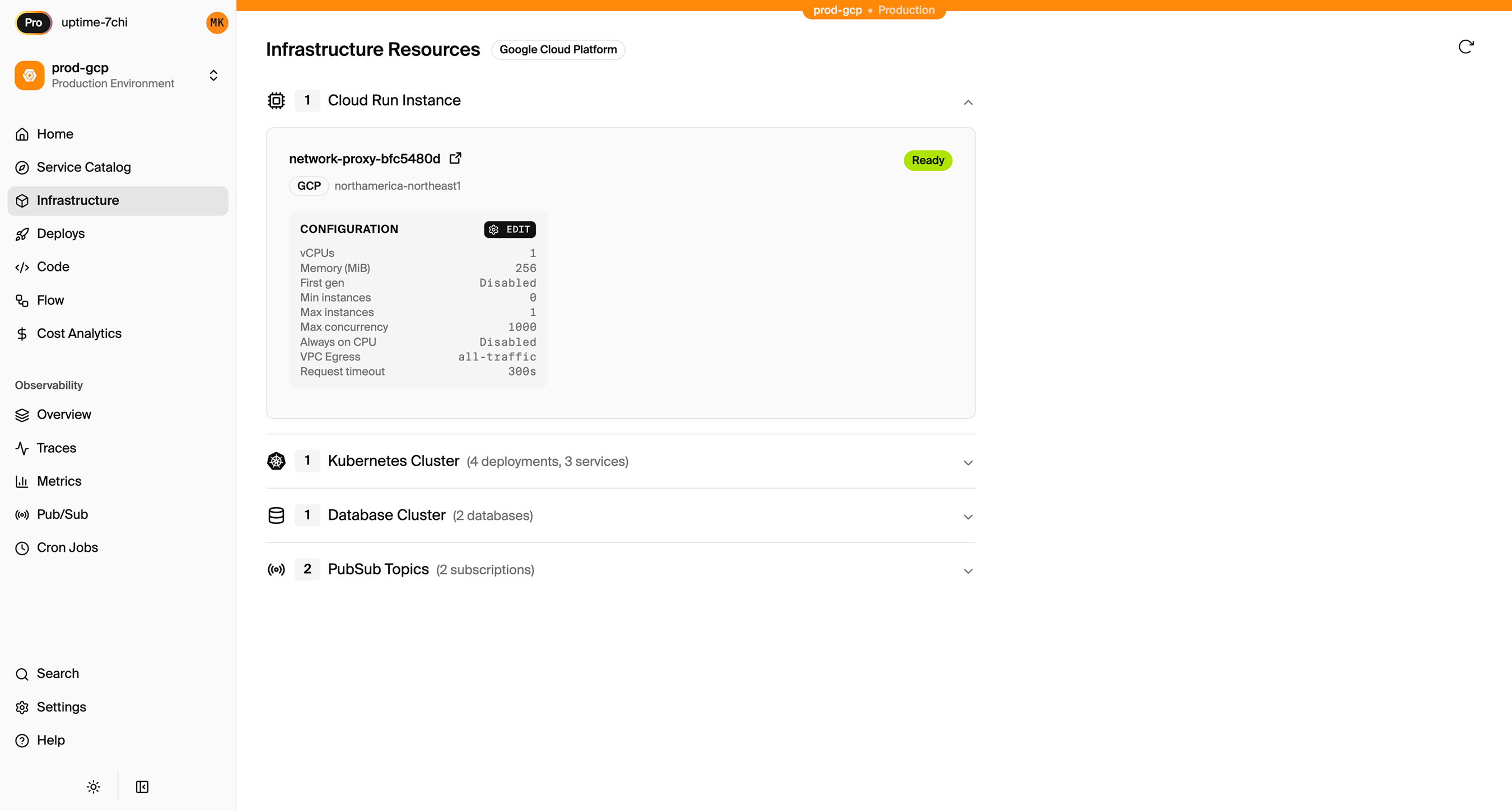
When an agent writes this, the output is deployable on git push. There's no second PR, no plan/apply cycle, no drift between application code and infrastructure state. There are also no .tf files with AWS account IDs or IAM policies sitting in the repo for AI tools to index and send to model providers. The agent produces a complete, working service, not half a service and a ticket for the platform team.
A harness for AI agents
With Terraform, an agent writing infrastructure has the full AWS or GCP API surface available to it. Every .tf file is unconstrained by default. With infrastructure from code, the agent writes new SQLDatabase("orders") and the platform decides what that means: private subnet, encryption at rest, automated backups, least-privilege IAM. The infrastructure team configures these constraints once per environment. Every service inherits the same guardrails regardless of who or what created it.
Encore's Rust-based parser adds compile-time validation on top. Wrong pub/sub payload type, missing migration directory, invalid API contract: these are compile errors, caught before anything deploys. The agent gets fast feedback in the same loop where it writes the code instead of three days later in a staging environment.
What we've learned building this
We've been building infrastructure from code at Encore for several years now, and some of what we learned was surprising.
Local infrastructure has to match production semantics. Early on, the temptation was to mock things locally and provision real infrastructure only in the cloud. That doesn't work. If the local database is a SQLite approximation, agents (and humans) write code that works locally and breaks in production. Encore provisions real Postgres locally through Docker and runs pub/sub and caching as semantically equivalent in-memory services. An agent writes a migration using jsonb_path_query or an ON CONFLICT clause, runs the tests, and the query works because it's running against real Postgres, not a SQLite stub that silently drops the syntax.
Agents need to see the running system, not just the code. We shipped an MCP server that gives AI tools structured access to service architecture, database schemas, distributed traces, and live API calls. Without schema access, an agent adding a field to an API response will guess column names. With the MCP server, it queries the actual schema and generates a correct join on the first try. Trace access means it can debug a slow endpoint by looking at real request timings instead of reading source code and speculating. We wrote about this more in How AI Agents Want to Write TypeScript.
The compile-time model is what makes it work. Encore parses your TypeScript at compile time using a Rust-based analyzer that builds a complete graph of services, APIs, and infrastructure dependencies. That model is what lets the platform provision infrastructure automatically, generate architecture diagrams, and set up observability without configuration. An agent creates a subscriber for an event topic with the wrong payload type? Compile error. A service references a database that doesn't have a matching migration directory? Compile error. These are things that would otherwise surface at runtime in staging, or worse, production.
Developers stop waiting for platform engineers. In a Terraform workflow, a developer who needs a database files a ticket. A platform engineer writes the module, reviews it, plans it, applies it. That handoff takes days. With infrastructure from code, a developer adds new SQLDatabase("orders") and the infrastructure follows within guardrails the infrastructure team configures once. The developer moves on to the next thing, and the same workflow that lets a human developer self-serve lets an agent self-serve.
Since adopting Encore, we've seen a 2-3x increase in development speed and 90% shorter project lead times. What used to take days or weeks of back-and-forth between developers and infra teams is now automated and completed in minutes.
 Josef SimaEngineering Director at Groupon
Josef SimaEngineering Director at GrouponThe thing we're still working on is making the agent onramp smoother. The MCP server, the LLM instruction files, and the skills package are a start, but there's more to do before an agent can go from a blank project to a deployed system without friction. That's the next step.
Why the switch is happening now
Backend technology choices used to be driven by developer preference: ecosystem familiarity, available talent, stylistic fit. Even when a new approach offered clear technical advantages, switching costs and cultural inertia kept teams on whatever they already knew. Terraform had years of accumulated investment, a massive ecosystem of modules, and an entire profession built around it. The case for something different had to be overwhelming, and it never was.
AI changes what drives these decisions. When code is increasingly generated rather than hand-written, the factors that kept teams on Terraform lose their weight. Familiarity with HCL syntax doesn't matter when the agent writes it. The talent pool for Terraform engineers doesn't matter when there's less Terraform to write. What matters instead is objective outcomes: deployment speed, failure rates, infrastructure drift, and how many tokens and review cycles it takes to get code running.
Infrastructure from code directly improves the outcomes that AI-forward teams are now optimizing for. No drift between codebases, no deployment friction, environment parity by default, and operational concerns handled automatically. The teams that switch aren't switching because IFC is theoretically better. They're switching because AI made the gap between theory and practice impossible to ignore.
Where it's all heading
The separation between application code and infrastructure code made sense when both were written by humans at a human pace. That assumption is changing fast. AI tools are already writing most of the application code in some organizations, and the infrastructure layer is the thing that determines whether that code actually runs or sits in a queue.
We recently published a whitepaper, Backend Development 3.0, that goes deeper into the data behind this shift, including DORA findings on AI adoption, infrastructure maturity models, and what the transition path looks like for teams moving off Terraform.
The companies that will move fastest with AI in backend development are the ones where infrastructure follows from the code automatically, where there's no step between writing code and running it.
Encore is an open-source backend framework where infrastructure is declared in TypeScript or Go and provisioned from the code. No Terraform, no YAML, no separate infrastructure repo. GitHub.
Related Articles

 Ivan Cernja
Ivan Cernja Ivan Cernja
Ivan Cernja Ivan Cernja
Ivan Cernja